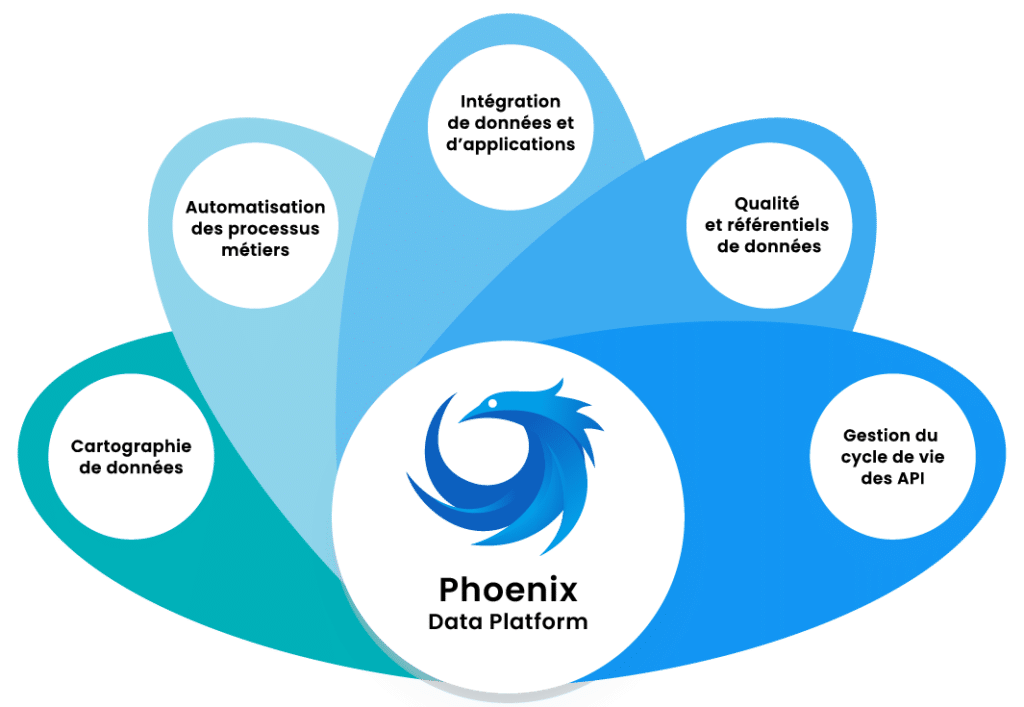
![]()
Comment améliorer le niveau
de conformité réglementaire ?
Les exigences réglementaires ne cessent d’évoluer et de se renforcer. Banques et assurances sont particulièrement exposées face à une volonté de plus de supervision clairement affichée par le régulateur. Répondre à cet enjeu constitue une nécessité non seulement pour éviter des amendes qui peuvent s’avérer colossales, mais aussi pour préserver le capital confiance des clients.
![]()
Normaliser et classifier
automatiquement les données
L’utilisation d’un outil de normalisation et classification automatique des données permet d’identifier de manière transverse l’existence de sources traitant des informations réglementées. En cas d’écart de conformité, l’outil permet également de faciliter la remédiation.
![]()
Comment faire face
au risque de fuite de données ?
La digitalisation des échanges a pour corollaire potentiel la dissémination d’informations sensibles dans des zones du SI qui n’ont pas été conçues pour les héberger. L’augmentation incontrôlée de la surface d’exposition peut résulter dans une perte de données dommageable à la compétitivité et à l’image, que ce soit en cas de cyberattaque ou de fraude interne.
Cartographier automatiquement toutes les sources de données
Grâce au catalogage automatique, il est possible de savoir instantanément où se trouvent les différentes typologies de données, avec leur niveau de criticité, afin de prendre les mesures de protection appropriées : effacement, déplacement, anonymisation… En programmant la fréquence d’exécution des scans, il est possible de gérer la cartographie en quasi-temps réelComment garantir le bon traitement et l’exploitabilité des données de référence ?
La fiabilisation des données de référence est un enjeu majeur pour améliorer la qualité des analyses et les prises de décisions stratégiques. Pour les banques et les assurances, il est également indispensable de pouvoir justifier auprès du régulateur de la traçabilité de bout en bout de certaines de ces données, lorsqu’elles font l’objet d’une déclaration obligatoire.![]()
Construire un référentiel centralisé
Une solution de catalogage associée à un système de data management (MDM) permet d’homogénéiser l’approche transverse autour des concepts clés, d’identifier la localisation des « golden data » correspondantes, et de procéder à la consolidation et au partage de ces données.
Comment s’ouvrir à l’écosystème de manière sûre et dynamique ?
Si les principes de l’open banking introduits par la PSD2 dès 2016 ont pu être initialement accueillis avec une certaine inquiétude tant ils changeaient la donne, leur application est maintenant largement répandue et a produit de premiers résultats observables en matière d’innovation. Sans revêtir le même caractère réglementaire, l’open insurance est aujourd’hui promue par de nombreux acteurs comme un levier de personnalisation de l’offre et d’amélioration de l’expérience client.Mettre en place un modèle de travail collaboratif de confiance
L’utilisation d’une solution de management des API permet de sécuriser l’ouverture des flux sur l’extérieur, notamment en termes de contrôle d’accès et de gestion des profils. Combinée avec un outil de catalogage, cette ouverture applicative peut s’accompagner de la mise à disposition de datasets collaboratifs, vecteurs d’innovation conjointe entre des détenteurs d’informations et des créateurs de services.
Disposer d’une vision holistique du patrimoine de données
exploitable et actualisée en permanence.

Augmenter le niveau de qualité
de la donnée applicative
et la maintenir dans le temps, pour améliorer la capacité décisionnelle et l’innovation.

Diffuser une culture data driven
au sein de l’organisation
en rendant les données utiles facilement accessibles et compréhensibles.

Satisfaire aux exigences réglementaires
qu'il s’agisse des traitements, de la conservation ou encore des obligations déclaratives.

Assurer une contribution effective de la donnée à la compétitivité,
que ce soit d’un point de vue défensif en contrôlant les coûts (optimisation d’architecture et d’infrastructure, limitation des risques en matière de perte de données, de fraudes, de risques d’amende, etc.) ou en générant des opportunités de revenus (fidélisation clients, ventes croisées, innovation, partenariats, etc.).