![]()
How to improve regulatory compliance?
Regulatory requirements are constantly evolving and becoming stricter. Banks and insurance companies are particularly exposed to the regulator’s clear desire for greater supervision. Meeting this challenge is a necessity, not only to avoid potentially colossal fines, but also to preserve customer confidence.
![]()
Standardize and classify data automatically
The use of an automatic data normalization and classification tool enables cross-functional identification of sources handling regulated information. In the event of non-compliance, the tool also facilitates remediation.
![]()
How to deal with the risk of data leakage?
The digitalization of exchanges has the potential corollary of disseminating sensitive information in areas of the IS that were not designed to house it. The uncontrolled increase in the surface area exposed can result in the loss of data, damaging both competitiveness and image, in the event of cyber-attack or internal fraud.
![]()
Automatically map all data sources
Thanks to automatic cataloguing, it is possible to know instantly where the various types of data are located, with their level of criticality, so that the appropriate protection measures can be taken: deletion, relocation, anonymization, etc. By programming the frequency of scans, it is possible to manage the cartography in near-real time.
![]()
How can we ensure that reference data is properly processed and usable?
The reliability of reference data is a major challenge for improving the quality of analyses and strategic decision-making. For banks and insurance companies, it is also essential to be able to justify to the regulator the end-to-end traceability of some of these data, when they are subject to mandatory reporting.
![]()
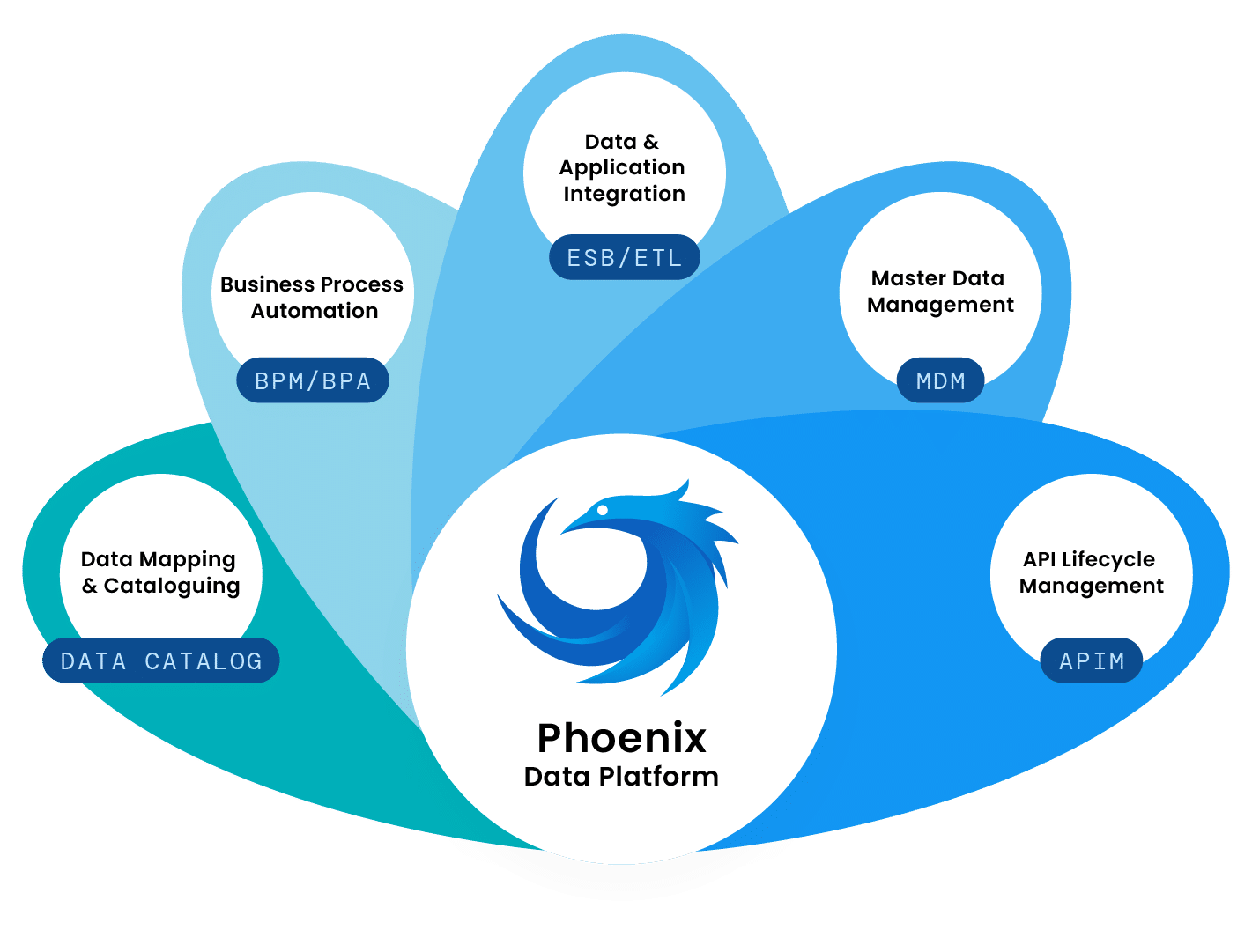
Building a centralized repository
A cataloging solution combined with a data management system (MDM) enables us to standardize our cross-functional approach to key concepts, identify the location of the corresponding “golden data”, and consolidate and share this data.
![]()
How to open up to the ecosystem in a safe and dynamic way?
While the principles of open banking introduced by PSD2 back in 2016 may initially have been greeted with some trepidation, so game-changing were they, their application is now widespread and has produced initial observable results in terms of innovation. Without having the same regulatory character, open insurance is now being promoted by many players as a lever for personalizing the offer and improving the customer experience.
![]()
Setting up a trusted collaborative working model
The use of an API management solution makes it possible to secure the opening of flows to the outside world, particularly in terms of access control and profile management. Combined with a cataloging tool, this application opening can be accompanied by the provision of collaborative datasets, vectors of joint innovation between information holders and service creators.

A holistic view of data assets
and constantly updated.

Increase the quality of application data
and maintain it over time, to improve decision-making capacity and innovation.

Spread a data-driven culture throughout the organization
by making useful data easily accessible and understandable.

Meeting regulatory requirements
whether in terms of processing, storage or reporting obligations.

Ensure that data makes an effective contribution to competitiveness
whether from a defensive point of view by controlling costs (optimizing architecture and infrastructure, limiting risks in terms of data loss, fraud, risk of fines, etc.) or by generating revenue opportunities (customer loyalty, cross-selling, innovation, partnerships, etc.).
"Our objective was to find a tool that could scan our servers according to our management criteria, report alerts and even purge and bring our office servers into compliance. Our review of the market led us to select the solution proposed by Dawizz."